¶ Webserver Logfile Analyse
¶ Matomo
Ich verzichte auf tracking per Javascript, Tracking-Bildern und son Zeug.
Es muss also ein Tool sein, welches die Webserver Logs direkt auswertet und auf dem Server ansehnlich aufbereitet.
Bisher nutze ich goaccess, das ist optisch sehr gut, kann sogar als Consolenprogramm live Daten mit ncurses aufbereitet darstellen und ist sehr nützlich.
Ausserdem kann man es ähnlich awstats den Site Besitzern als Statistik Tool zur Verfügung stellen.
Aber das neue ist des guten althergebrachten sein Feind.
Ausser Matomo gibt es auch noch andere Tools, die man ausprobieren kann, wie z.B. umami.
Doch nun zu Matomo
¶ Installation
matomo-latest.zipbesorgen und auf dem Server in dem vorgesehenen Web entpacken.- matomo Setie aufrufen, und konfigurieren.
- Gegen Ende der Installation kommen die Möglichkeiten für Tracking Script und andere Dinge, das verneint man.
- dann ist man eigentlich fertig und kann die Installation als beendet betrachten, ich fand die weiteren Erläuterungen eher verwirrend als hilfreich.
¶ Webserver Logs importieren
Wie kommt matomo an die Daten?
-
So:
Testlauf
python3 /var/www/fuermatomo.de/web/matomo/misc/log-analytics/import_logs.py --url https://fuermatomo.de/matomo /var/www/daucity.de/log/access.log --idsite 1 -
zweiter Teil
php8.2 /var/www/fuermatomo.de/web/matomo/console core:archive
¶ Matomo aufrufen
Das ist eigentlich selbsterklärend.
Hier im Screenshot sieht man ein nachträglich via Marketplace nachinstalliertes plugin, welches die Bots auswertet.
¶ Automatisch die Auswertung aktualisieren
Ich mache das via Cron als www-data
su - www-data -s /bin/bash zum testen
crontab -u www-data -e
# E-Mail-Versand bei Fehlern aktivieren
MAILTO="admin@matomosite.de"
# PHP Version
PHP="/usr/bin/php8.2"
#
# m h dom mon dow command
# Für die 3 Domains von matomo jede halbe Stunde
# Hier stellvertretend nur eine domain
1,31 * * * * /usr/bin/python3 /var/www/matomosite.de/web/matomo/misc/log-analytics/import_logs.py --url https://matomosite.de/matomo /var/www/daucity.de/log/acess.log --idsite 1 >> /var/log/matomo_import_logs_site1.log #2>&1 >/dev/null
# core:archive übernimmt die restarbeeiten für berichte u.a.
4,34 * * * * $PHP /var/www/matomosite.de/web/matomo/console core:archive >> /var/log/matomo_archive.log 2>&1
Wenn das geklappt hat, kann man auch ältere Logfiles erfassen, das geht sehr einfach, weil der matomo import mit komprimierten Logsfiles umgehen kann.
Also sowas wie:
python3 import_logs.py --url https://matomosite.de/matomo /var/www/daucity.de/log/202407* --idsite 1 funktioniert einwandfrei, danach den core:archive job starten, oder abwaten, bis cron das erledigt.
Zum regelmässigen Aufruf in cron habe ich jetzt noch die Schalter --enable-http-errors , --enable-http-redirects und --request-timeout 30 hinzugefügt.
Damit ist zum Beispiel so eine Auswertung möglich.
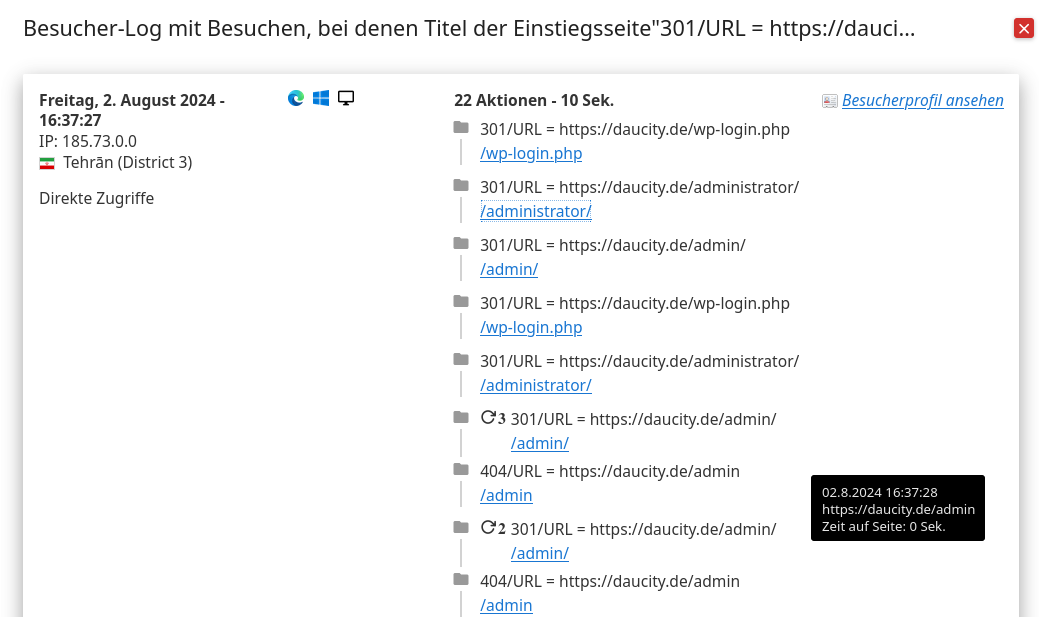
HTTP-Fehler: Damit kann man sehen, wie oft und welche Fehler auftreten. Das kann helfen, Probleme wie fehlende Seiten (404-Fehler) oder Serverprobleme (500er-Fehler) zu identifizieren und zu beheben.
HTTP-Weiterleitungen: Die Analyse von Weiterleitungen zeigt, ob sie korrekt eingerichtet sind und ob Besucher oft umgeleitet werden, was auf mögliche Probleme wie fehlerhafte Links oder unnötige Weiterleitungsketten hinweisen könnte.
Sollte jemand jetzt auch matomo installieren und feststellen, dass meine Anleitung arg knapp ist, dann bitte melden.
¶ Plugins
Es gibt etliche Plugins, auch freie, kostenlose.
Ich habe das Plugin BotTracker
installiert.
Das funktioniert auf Anhieb für beireits eingerichteten Sites.
Für nach der Installlation des BotTrackers hinzugefügte Sites ist das nicht der Fall.
Da muß in den Einstellungen des BotTracker jede neu hinzugefügte Site einzeln im Bot-Tracker-Plugin konfiguriert werden, damit die Bots korrekt erkannt und getrackt werden.
Die Einstellungen beschränken sich darauf, dass man die default Bots hinzufügt.
Siehe Screenshots.
![]()
![]()
Und speichern der Einstellungen nicht vergessen!
So sieht das beispielsweise aus
![]()